Publications
2024
-
 The structure and function of antagonistic ties in village social networksAmir Ghasemian, and Nicholas A ChristakisProceedings of the National Academy of Sciences, 2024Image courtesy of Cavan Huang
The structure and function of antagonistic ties in village social networksAmir Ghasemian, and Nicholas A ChristakisProceedings of the National Academy of Sciences, 2024Image courtesy of Cavan HuangNegative or antagonistic relationships are common in human social networks, but they are less often studied than positive or friendly relationships. The existence of a capacity to have and to track antagonistic ties raises the possibility that they may serve a useful function in human groups. Here, we analyze empirical data gathered from 24,770 and 22,513 individuals in 176 rural villages in Honduras in two survey waves 2.5 y apart in order to evaluate the possible relevance of antagonistic relationships for broader network phenomena. We find that the small-world effect is more significant in a positive world with negative ties compared to an otherwise similar hypothetical positive world without them. Additionally, we observe that nodes with more negative ties tend to be located near network bridges, with lower clustering coefficients, higher betweenness centralities, and shorter average distances to other nodes in the network. Positive connections tend to have a more localized distribution, while negative connections are more globally dispersed within the networks. Analysis of the possible impact of such negative ties on dynamic processes reveals that, remarkably, negative connections can facilitate the dissemination of information (including novel information experimentally introduced into these villages) to the same degree as positive connections, and that they can also play a role in mitigating idea polarization within village networks. Antagonistic ties hold considerable importance in shaping the structure and function of social networks.
@article{ghasemian2024strfun, title = {The structure and function of antagonistic ties in village social networks}, author = {Ghasemian, Amir and Christakis, Nicholas A}, journal = {Proceedings of the National Academy of Sciences}, volume = {121}, number = {26}, pages = {e2401257121}, year = {2024}, publisher = {National Acad Sciences}, note = {Image courtesy of Cavan Huang}, project = {/projects/StrFunAntTies/} } -
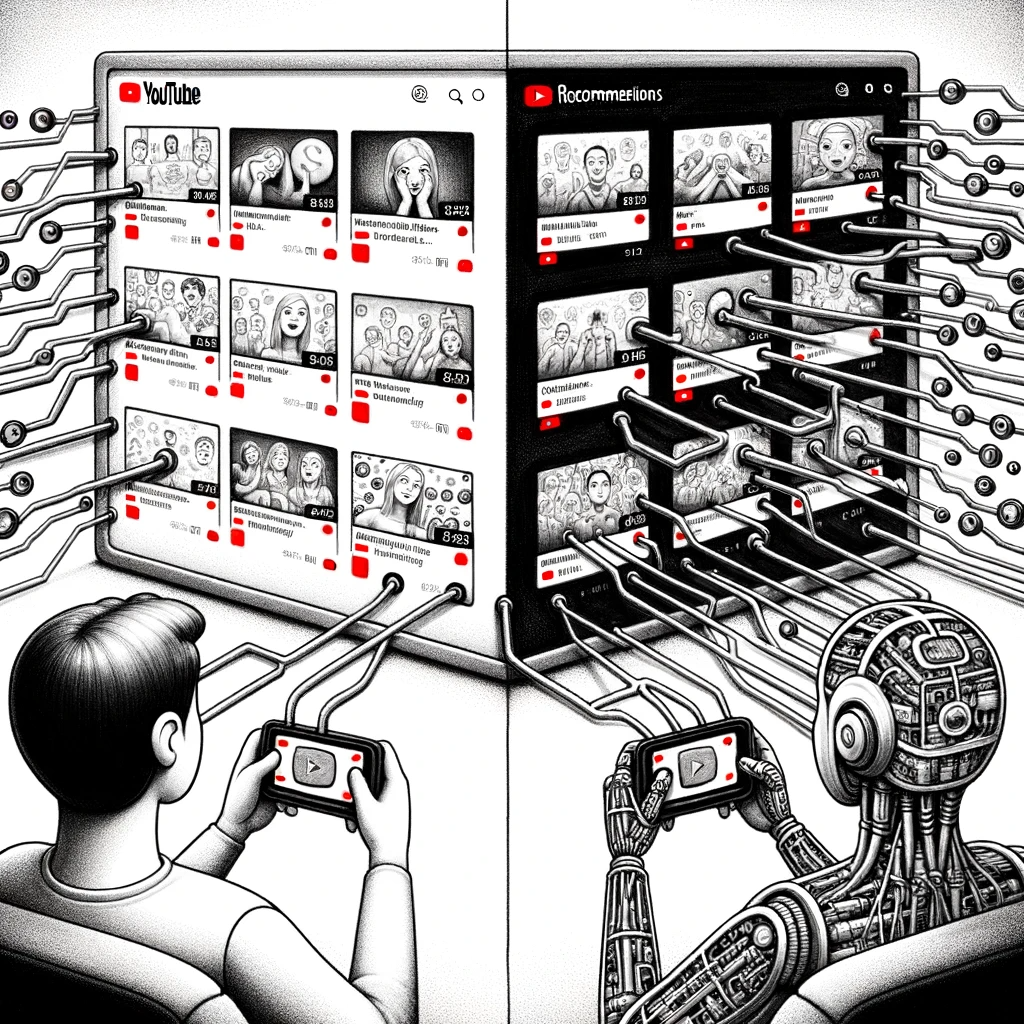 Causally estimating the effect of YouTube’s recommender system using counterfactual botsHoma Hosseinmardi, Amir Ghasemian, Miguel Rivera-Lanas, and 3 more authorsProceedings of the National Academy of Sciences, 2024
Causally estimating the effect of YouTube’s recommender system using counterfactual botsHoma Hosseinmardi, Amir Ghasemian, Miguel Rivera-Lanas, and 3 more authorsProceedings of the National Academy of Sciences, 2024In recent years, critics of online platforms have raised concerns about the ability of recommendation algorithms to amplify problematic content, with potentially radicalizing consequences. However, attempts to evaluate the effect of recommenders have suffered from a lack of appropriate counterfactuals – what a user would have viewed in the absence of algorithmic recommendations – and hence cannot disentangle the effects of the algorithm from a user’s intentions. Here we propose a method that we call "counterfactual bots" to causally estimate the role of algorithmic recommendations on the consumption of highly partisan content. By comparing bots that replicate real users’ consumption patterns with "counterfactual" bots that follow rule-based trajectories, we show that, on average, relying exclusively on the recommender results in less partisan consumption, where the effect is most pronounced for heavy partisan consumers. Following a similar method, we also show that if partisan consumers switch to moderate content, YouTube’s sidebar recommender "forgets" their partisan preference within roughly 30 videos regardless of their prior history, while homepage recommendations shift more gradually towards moderate content. Overall, our findings indicate that, at least on YouTube, individual consumption patterns mostly reflect individual preferences, where algorithmic recommendations play, if anything, a moderating role.
@article{hosseinmardi2023causally, title = {Causally estimating the effect of YouTube's recommender system using counterfactual bots}, author = {Hosseinmardi, Homa and Ghasemian, Amir and Rivera-Lanas, Miguel and Ribeiro, Manoel Horta and West, Robert and Watts, Duncan J}, journal = {Proceedings of the National Academy of Sciences}, volume = {121}, number = {8}, pages = {e2313377121}, year = {2024}, publisher = {National Acad Sciences}, project = {/projects/CausalEstYTRecomSystCountBots/} } -
%20representing%20different%20time%20snapshots%20of%20a%20temporal%20network.%20Arrows%20move%20upwards%20fr.png) Sequential Stacking Link Prediction Algorithms for Temporal NetworksXie He, Amir Ghasemian, Eun Lee, and 2 more authorsNature Communications, 2024
Sequential Stacking Link Prediction Algorithms for Temporal NetworksXie He, Amir Ghasemian, Eun Lee, and 2 more authorsNature Communications, 2024Link prediction algorithms are indispensable tools in many scientific applications by speeding up network data collection and imputing missing connections. However, in many systems, links change over time and it remains unclear how to optimally exploit such temporal information for link predictions in such networks. Here, we show that many temporal topological features, in addition to having high computational cost, are less accurate in temporal link prediction than sequentially stacked static network features. This sequential stacking link prediction method uses 41 static network features that avoids detailed feature engineering choices and is capable of learning a highly accurate predictive distribution of future connections from historical data. We demonstrate that this algorithm works well for both partially observed and completely unobserved target layers, and achieves near-optimal AUC on two temporal stochastic block models. Finally, we empirically illustrate that stacking multiple predictive methods together further improves performance on 19 real-world temporal networks from different domains.
@article{he2023sequential, title = {Sequential Stacking Link Prediction Algorithms for Temporal Networks}, author = {He, Xie and Ghasemian, Amir and Lee, Eun and Clauset, Aaron and Mucha, Peter}, journal = {Nature Communications}, volume = {15}, issue = {1}, pages = {1364}, year = {2024}, project = {/projects/SeqStacking/}, } -
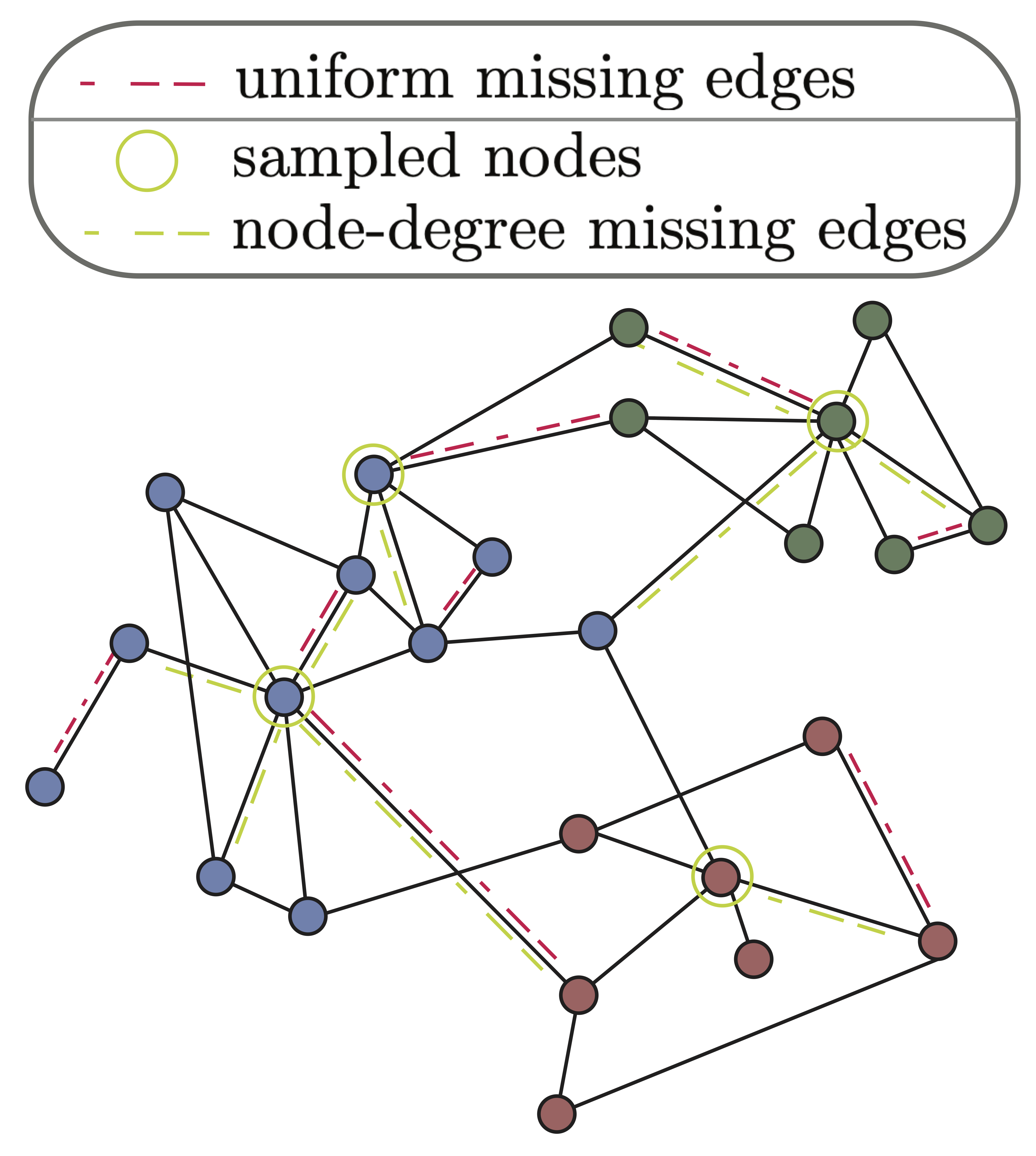 Link Prediction Accuracy on Real-World Networks Under Non-Uniform Missing Edge PatternsXie He, Amir Ghasemian, Eun Lee, and 3 more authorsPloS one, 2024
Link Prediction Accuracy on Real-World Networks Under Non-Uniform Missing Edge PatternsXie He, Amir Ghasemian, Eun Lee, and 3 more authorsPloS one, 2024Real-world network datasets are typically obtained in ways that fail to capture all edges. The patterns of missing data are often non-uniform as they reflect biases and other shortcomings of different data collection methods. Nevertheless, uniform missing data is a common assumption made when no additional information is available about the underlying missing-edge pattern, and link prediction methods are frequently tested against uniformly missing edges. To investigate the impact of different missing-edge patterns on link prediction accuracy, we employ 9 link prediction algorithms from 4 different families to analyze 20 different missing-edge patterns that we categorize into 5 groups. Our comparative simulation study, spanning 250 real-world network datasets from 6 different domains, provides a detailed picture of the significant variations in the performance of different link prediction algorithms in these different settings. With this study, we aim to provide a guide for future researchers to help them select a link prediction algorithm that is well suited to their sampled network data, considering the data collection process and application domain.
@article{he2023sampling, title = {Link Prediction Accuracy on Real-World Networks Under Non-Uniform Missing Edge Patterns}, author = {He, Xie and Ghasemian, Amir and Lee, Eun and Schwarze, Alice and Clauset, Aaron and Mucha, Peter J}, journal = {PloS one}, volume = {19}, number = {7}, pages = {e0306883}, year = {2024}, publisher = {Public Library of Science San Francisco, CA USA}, project = {/projects/NonUniformSampling/}, }
2023
-
 The Enmity ParadoxAmir Ghasemian, and Nicholas A ChristakisScientific Reports, 2023
The Enmity ParadoxAmir Ghasemian, and Nicholas A ChristakisScientific Reports, 2023The "friendship paradox" of social networks states that, on average, "your friends have more friends than you do." Here, we theoretically and empirically explore a related and overlooked paradox we refer to as the "enmity paradox." We use empirical data from 24,687 people living in 176 villages in rural Honduras. We show that, for a real negative undirected network (created by symmetrizing antagonistic interactions), the paradox exists as it does in the positive world. Specifically, a person’s enemies have more enemies, on average, than a person does. Furthermore, in a mixed world of positive and negative ties, we study the conditions for the existence of the paradox, both theoretically and empirically, finding that, for instance, a person’s friends typically have more enemies than a person does. We also confirm the "generalized" enmity paradox for nontopological attributes in real data, analogous to the generalized friendship paradox (e.g., the claim that a person’s enemies are richer, on average, than a person is). As a consequence, the naturally occurring variance in the degree distribution of both friendship and antagonism in social networks can skew people’s perceptions of the social world.
@article{ghasemian2023enmity, title = {The Enmity Paradox}, author = {Ghasemian, Amir and Christakis, Nicholas A}, journal = {Scientific Reports}, volume = {13}, issue = {1}, pages = {20040}, year = {2023}, project = {/projects/EnmityParadox/}, } -
%20approaching%20from%20different%20directions.%20Overlaid%20are%20subspace%20plots%20that%20ca.png) Subspace based DOA estimation of DS-CDMA signalsAmir Ghasemian, Ali Olfat, and Mojtaba AmiriTelecommunication Systems, 2023
Subspace based DOA estimation of DS-CDMA signalsAmir Ghasemian, Ali Olfat, and Mojtaba AmiriTelecommunication Systems, 2023This paper presents a subspace blind method to estimate the direction of arrival of direct sequence code division multiple access signals in a multipath fading environment. The proposed method is based on signal/noise subspace approach. For enhancing the results, the problem is formulated based on both signal and noise subspaces to exploit structures of desired signal, self interference and multiple access interference simultaneously. The main idea in this paper is based on fitting the extended subspace spanned by the desired signature waveform in all different paths into the estimated extended signal subspace. The proposed method is blind in the sense that it utilizes only the desired user’s code and its corresponding path delays. The performance of the proposed method is compared to the Cramer–Rao lower bound. We also propose a method for estimating relative power of different paths in multipath code division multiple access signals.
@article{ghasemian2023subspace, title = {Subspace based DOA estimation of DS-CDMA signals}, author = {Ghasemian, Amir and Olfat, Ali and Amiri, Mojtaba}, journal = {Telecommunication Systems}, pages = {1--12}, year = {2023}, publisher = {Springer}, project = {/projects/DOA_CDMA/} } -
 Tensor embedding: a supervised framework for human behavioral data mining and predictionHoma Hosseinmardi, Amir Ghasemian, Shrikanth Narayanan, and 2 more authorsIn 2023 IEEE 11th International Conference on Healthcare Informatics (ICHI), 2023
Tensor embedding: a supervised framework for human behavioral data mining and predictionHoma Hosseinmardi, Amir Ghasemian, Shrikanth Narayanan, and 2 more authorsIn 2023 IEEE 11th International Conference on Healthcare Informatics (ICHI), 2023Today’s densely instrumented world offers tremendous opportunities for continuous acquisition and analysis of multimodal sensor data providing temporal characterization of an individual’s behaviors. Is it possible to efficiently couple such rich sensor data with predictive modeling techniques to provide contextual, and insightful assessments of individual performance and wellbeing? Prediction of different aspects of human behavior from these noisy, incomplete, and heterogeneous bio-behavioral temporal data is a challenging problem, beyond unsupervised discovery of latent structures. We propose a Supervised Tensor Embedding (STE) algorithm for high dimension multimodal data with join decomposition of input and target variable. Furthermore, we show that features selection will help to reduce the contamination in the prediction and increase the performance. The efficiently of the methods was tested via two different real world datasets.
@inproceedings{hosseinmardi2018tensor, title = {Tensor embedding: a supervised framework for human behavioral data mining and prediction}, author = {Hosseinmardi, Homa and Ghasemian, Amir and Narayanan, Shrikanth and Lerman, Kristina and Ferrara, Emilio}, booktitle = {2023 IEEE 11th International Conference on Healthcare Informatics (ICHI)}, pages = {91--100}, year = {2023}, organization = {IEEE}, }
2021
-
 Examining the consumption of radical content on YouTubeHoma Hosseinmardi, Amir Ghasemian, Aaron Clauset, and 3 more authorsProceedings of the National Academy of Sciences, 2021
Examining the consumption of radical content on YouTubeHoma Hosseinmardi, Amir Ghasemian, Aaron Clauset, and 3 more authorsProceedings of the National Academy of Sciences, 2021Although it is under-studied relative to other social media platforms, YouTube is arguably the largest and most engaging online media consumption platform in the world. Recently, YouTube’s scale has fueled concerns that YouTube users are being radicalized via a combination of biased recommendations and ostensibly apolitical “anti-woke” channels, both of which have been claimed to direct attention to radical political content. Here we test this hypothesis using a representative panel of more than 300,000 Americans and their individual-level browsing behavior, on and off YouTube, from January 2016 through December 2019. Using a labeled set of political news channels, we find that news consumption on YouTube is dominated by mainstream and largely centrist sources. Consumers of far-right content, while more engaged than average, represent a small and stable percentage of news consumers. However, consumption of “anti-woke” content, defined in terms of its opposition to progressive intellectual and political agendas, grew steadily in popularity and is correlated with consumption of far-right content off-platform. We find no evidence that engagement with far-right content is caused by YouTube recommendations systematically, nor do we find clear evidence that anti-woke channels serve as a gateway to the far right. Rather, consumption of political content on YouTube appears to reflect individual preferences that extend across the web as a whole.
@article{hosseinmardi2021examining, title = {Examining the consumption of radical content on YouTube}, author = {Hosseinmardi, Homa and Ghasemian, Amir and Clauset, Aaron and Mobius, Markus and Rothschild, David M and Watts, Duncan J}, journal = {Proceedings of the National Academy of Sciences}, volume = {118}, number = {32}, pages = {e2101967118}, year = {2021}, publisher = {National Acad Sciences}, project = {/projects/YTAuditing/} }
2020
-
 Stacking models for nearly optimal link prediction in complex networksAmir Ghasemian, Homa Hosseinmardi, Aram Galstyan, and 2 more authorsProceedings of the National Academy of Sciences, 2020
Stacking models for nearly optimal link prediction in complex networksAmir Ghasemian, Homa Hosseinmardi, Aram Galstyan, and 2 more authorsProceedings of the National Academy of Sciences, 2020Most real-world networks are incompletely observed. Algorithms that can accurately predict which links are missing can dramatically speed up network data collection and improve network model validation. Many algorithms now exist for predicting missing links, given a partially observed network, but it has remained unknown whether a single best predictor exists, how link predictability varies across methods and networks from different domains, and how close to optimality current methods are. We answer these questions by systematically evaluating 203 individual link predictor algorithms, representing three popular families of methods, applied to a large corpus of 550 structurally diverse networks from six scientific domains. We first show that individual algorithms exhibit a broad diversity of prediction errors, such that no one predictor or family is best, or worst, across all realistic inputs. We then exploit this diversity using network-based metalearning to construct a series of “stacked” models that combine predictors into a single algorithm. Applied to a broad range of synthetic networks, for which we may analytically calculate optimal performance, these stacked models achieve optimal or nearly optimal levels of accuracy. Applied to real-world networks, stacked models are superior, but their accuracy varies strongly by domain, suggesting that link prediction may be fundamentally easier in social networks than in biological or technological networks. These results indicate that the state of the art for link prediction comes from combining individual algorithms, which can achieve nearly optimal predictions. We close with a brief discussion of limitations and opportunities for further improvements.
@article{ghasemian2020stacking, title = {Stacking models for nearly optimal link prediction in complex networks}, author = {Ghasemian, Amir and Hosseinmardi, Homa and Galstyan, Aram and Airoldi, Edoardo M and Clauset, Aaron}, journal = {Proceedings of the National Academy of Sciences}, volume = {117}, number = {38}, pages = {23393--23400}, year = {2020}, publisher = {National Acad Sciences}, project = {/projects/OptimalLinkPrediction/}, }
2019
-
 Limits of model selection, link prediction, and community detection (PhD Thesis)University of Colorado at Boulder, 2019
Limits of model selection, link prediction, and community detection (PhD Thesis)University of Colorado at Boulder, 2019Networks provide powerful representations of complex real-world systems across diverse domains including social science, biology, economics, and physics. Despite their apparent simplicity compared to the original systems, extracting meaningful patterns from network data presents substantial challenges. This dissertation addresses fundamental questions in network inference along two complementary lines: experimental analyses and theoretical limitations.
In the experimental component, we first investigate community detection, examining over- and underfitting behavior across 16 state-of-the-art algorithms applied to a novel benchmark corpus of 572 structurally diverse real-world networks. We find that algorithms vary widely in their outputs, can be clustered into distinct groups based on behavior on real networks, and that no single algorithm dominates across all inputs. We then turn to link prediction, providing a methodological overview and investigating optimal prediction capacity through supervised information fusion, as well as transfer learning across network domains.
In the theoretical component, we study fundamental limits of community detection in dynamic networks. Using the cavity method, we derive precise detectability thresholds for a dynamic stochastic block model where nodes change community memberships over time. We propose two asymptotically optimal algorithms—belief propagation and a fast spectral method—that succeed down to this threshold. We then extend this framework by incorporating link persistency, where edges appear or disappear gradually rather than suddenly, and investigate how this additional structure affects detectability limits.
Together, these contributions advance both practical understanding of algorithm performance on real networks and theoretical knowledge of fundamental limits in dynamic network inference.@phdthesis{ghasemian2019limits, title = {Limits of model selection, link prediction, and community detection (PhD Thesis)}, year = {2019}, school = {University of Colorado at Boulder}, } -
 Evaluating overfit and underfit in models of network community structureAmir Ghasemian, Homa Hosseinmardi, and Aaron ClausetIEEE Transactions on Knowledge and Data Engineering, 2019
Evaluating overfit and underfit in models of network community structureAmir Ghasemian, Homa Hosseinmardi, and Aaron ClausetIEEE Transactions on Knowledge and Data Engineering, 2019A common graph mining task is community detection, which seeks an unsupervised decomposition of a network into groups based on statistical regularities in network connectivity. Although many such algorithms exist, community detection’s No Free Lunch theorem implies that no algorithm can be optimal across all inputs. However, little is known in practice about how different algorithms over or underfit to real networks, or how to reliably assess such behavior across algorithms. Here, we present a broad investigation of over and underfitting across 16 state-of-the-art community detection algorithms applied to a novel benchmark corpus of 572 structurally diverse real-world networks. We find that (i) algorithms vary widely in the number and composition of communities they find, given the same input; (ii) algorithms can be clustered into distinct high-level groups based on similarities of their outputs on real-world networks; (iii) algorithmic differences induce wide variation in accuracy on link-based learning tasks; and, (iv) no algorithm is always the best at such tasks across all inputs. Finally, we quantify each algorithm’s overall tendency to over or underfit to network data using a theoretically principled diagnostic, and discuss the implications for future advances in community detection.
@article{ghasemian2019evaluating, title = {Evaluating overfit and underfit in models of network community structure}, author = {Ghasemian, Amir and Hosseinmardi, Homa and Clauset, Aaron}, journal = {IEEE Transactions on Knowledge and Data Engineering}, volume = {32}, number = {9}, pages = {1722--1735}, year = {2019}, publisher = {IEEE}, href = {https://journals.aps.org/prx/abstract/10.1103/PhysRevX.6.031005}, project = {/projects/CommunityFitNet/}, }
2016
-
 Detectability thresholds and optimal algorithms for community structure in dynamic networksAmir Ghasemian, Pan Zhang, Aaron Clauset, and 2 more authorsPhysical Review X, 2016
Detectability thresholds and optimal algorithms for community structure in dynamic networksAmir Ghasemian, Pan Zhang, Aaron Clauset, and 2 more authorsPhysical Review X, 2016The detection of communities within a dynamic network is a common means for obtaining a coarse-grained view of a complex system and for investigating its underlying processes. While a number of methods have been proposed in the machine learning and physics literature, we lack a theoretical analysis of their strengths and weaknesses, or of the ultimate limits on when communities can be detected. Here, we study the fundamental limits of detecting community structure in dynamic networks. Specifically, we analyze the limits of detectability for a dynamic stochastic block model where nodes change their community memberships over time, but where edges are generated independently at each time step. Using the cavity method, we derive a precise detectability threshold as a function of the rate of change and the strength of the communities. Below this sharp threshold, we claim that no efficient algorithm can identify the communities better than chance. We then give two algorithms that are optimal in the sense that they succeed all the way down to this threshold. The first uses belief propagation, which gives asymptotically optimal accuracy, and the second is a fast spectral clustering algorithm, based on linearizing the belief propagation equations. These results extend our understanding of the limits of community detection in an important direction, and introduce new mathematical tools for similar extensions to networks with other types of auxiliary information.
@article{ghasemian2016detectability, title = {Detectability thresholds and optimal algorithms for community structure in dynamic networks}, author = {Ghasemian, Amir and Zhang, Pan and Clauset, Aaron and Moore, Cristopher and Peel, Leto}, journal = {Physical Review X}, volume = {6}, number = {3}, pages = {031005}, year = {2016}, publisher = {APS}, project = {/projects/CommunityDetectability/}, }
2014
-
 Towards understanding cyberbullying behavior in a semi-anonymous social networkHoma Hosseinmardi, Amir Ghasemian, Richard Han, and 2 more authorsIn 2014 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2014), 2014
Towards understanding cyberbullying behavior in a semi-anonymous social networkHoma Hosseinmardi, Amir Ghasemian, Richard Han, and 2 more authorsIn 2014 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2014), 2014Cyberbullying has emerged as an important and growing social problem, wherein people use online social networks and mobile phones to bully victims with offensive text, images, audio and video on a 24/7 basis. This paper studies negative user behavior in the Ask.fm social network, a popular new site that has led to many cases of cyberbullying, some leading to suicidal behavior.We examine the occurrence of negative words in Ask.fm’s question+answer profiles along with the social network of “likes” of questions+answers. We also examine properties of users with “cutting” behavior in this social network.
@inproceedings{hosseinmardi2014towards, title = {Towards understanding cyberbullying behavior in a semi-anonymous social network}, author = {Hosseinmardi, Homa and Ghasemian, Amir and Han, Richard and Lv, Qin and Mishra, Shivakant}, booktitle = {2014 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2014)}, pages = {244--252}, year = {2014}, organization = {IEEE}, }