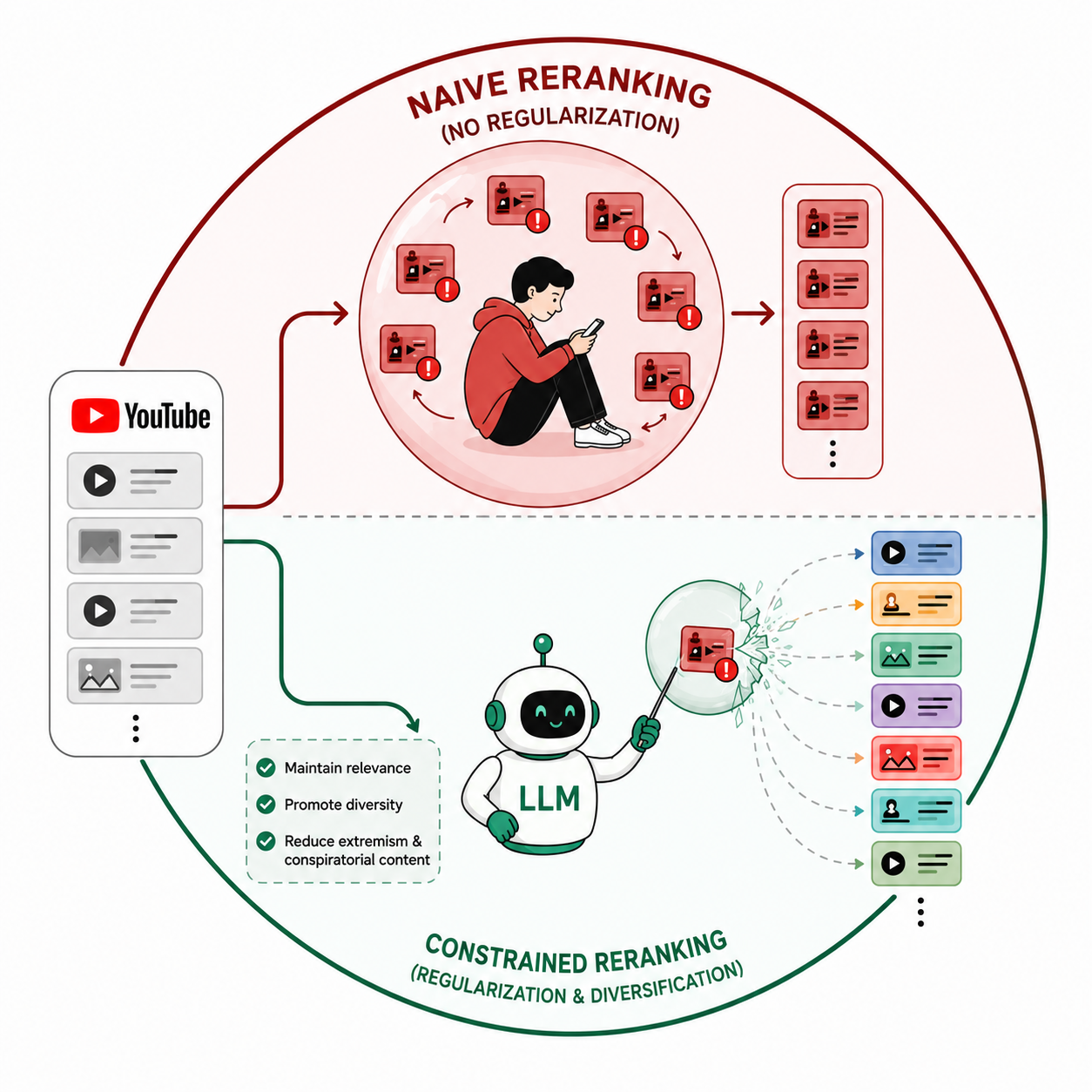
LLM-Assisted Reranking to Operationalize Nuanced Objectives in Recommender Systems
Recommender systems have grown from basic content-organization tools into sophisticated systems that subtly shape our daily behavior. By controlling what information we see, they can influence the world we perceive, raising concerns about filter bubbles, radicalization, polarization, and social inequality. The rise of large language models (LLMs) enables more powerful personalization, potentially intensifying these exposure dynamics. Yet most recommenders are tuned for engagement or limited accuracy metrics, with little attention to their broader social implications, e.g., how personalization reshapes content exposure in socially consequential domains. We investigate whether LLM-assisted reranking, while improving personalization, inadvertently amplifies exposure to ideologically extreme or conspiratorial political content—a risk theorized but not empirically characterized in news recommendation. Using real news-consumption histories, we rerank YouTube's sidebar candidates through zero-shot, instruction-based prompting. We compare a baseline personalization prompt with an instructionally constrained variant intended to preserve topical relevance and broaden ideological exposure, while reducing the prominence of conspiratorial or extreme political content. Without constraints, LLM-assisted reranking strengthened personalization but increased exposure to conspiratorial and extremist material for users whose histories contained such content. Adding lightweight prompt-level regularization reduced the likelihood of promoting extreme content and increased ideological diversity, with only modest loss in relevance. Synthetic experiments further suggest that LLMs rerank via statistical regularities in language rather than semantic understanding of ideology, clarifying both why naive prompts amplify these patterns and why prompt-level regularization can reshape them. Together, our results highlight the power of LLMs to operationalize contextual nuance in high-stakes news recommendation. They also underscore the need to evaluate LLM-assisted personalization beyond accuracy alone and to recognize prompt design as a value-laden choice rather than a neutral default.
Comparison of topical relevance and ideological scores for YT, emb+YT, bLLM+YT, and rLLM+YT across two right-leaning trajectories: right and right-right. Marker colors represent average ideological scores across recommendation ranks; error bars indicate the standard error of the mean topical match across sessions within each trajectory.
Two synthetic-session designs for distinguishing whether algorithms prioritize topic relevance or partisan alignment. (A) Histories cover a single topic with extreme partisanship (right-right or left-left); candidates include same-topic videos from the opposing extreme and other-topic videos sharing the history's partisan stance. (B) Histories cover a single topic with consistent partisan content (left-left, left, right, or right-right); candidates include same-topic videos spanning the full partisan spectrum.
Comparison of topical relevance and ideological scores for bLLM+YT and emb+YT, using synthetic sessions designed to test whether algorithms prioritize topic relevance or partisan alignment (Experiment 1; Fig. 4A). Sessions were constructed with extreme-leaning histories (left-left and right-right) on abortion, immigration, and elections. Marker colors represent average ideological scores across recommendation ranks; error bars show the standard error of topical match across sessions within each trajectory.
References
2026
LLM-Assisted Reranking to Operationalize Nuanced Objectives in Recommender Systems
Amir Ghasemian, Homa Hosseinmardi, Upasana Dutta, and 1 more author
Recommender systems have grown from basic content-organization tools into sophisticated systems that subtly shape our daily behavior. By controlling what information we see, they can influence the world we perceive, raising concerns about filter bubbles, radicalization, polarization, and social inequality. The rise of large language models (LLMs) enables more powerful personalization, potentially intensifying these exposure dynamics. Yet most recommenders are tuned for engagement or limited accuracy metrics, with little attention to their broader social implications, e.g., how personalization reshapes content exposure in socially consequential domains. We investigate whether LLM-assisted reranking, while improving personalization, inadvertently amplifies exposure to ideologically extreme or conspiratorial political content—a risk theorized but not empirically characterized in news recommendation. Using real news-consumption histories, we rerank YouTube’s sidebar candidates through zero-shot, instruction-based prompting. We compare a baseline personalization prompt with an instructionally constrained variant intended to preserve topical relevance and broaden ideological exposure, while reducing the prominence of conspiratorial or extreme political content. Without constraints, LLM-assisted reranking strengthened personalization but increased exposure to conspiratorial and extremist material for users whose histories contained such content. Adding lightweight prompt-level regularization reduced the likelihood of promoting extreme content and increased ideological diversity, with only modest loss in relevance. Synthetic experiments further suggest that LLMs rerank via statistical regularities in language rather than semantic understanding of ideology, clarifying both why naive prompts amplify these patterns and why prompt-level regularization can reshape them. Together, our results highlight the power of LLMs to operationalize contextual nuance in high-stakes news recommendation. They also underscore the need to evaluate LLM-assisted personalization beyond accuracy alone and to recognize prompt design as a value-laden choice rather than a neutral default.
@article{ghasemian2026llm,title={LLM-Assisted Reranking to Operationalize Nuanced Objectives in Recommender Systems},author={Ghasemian, Amir and Hosseinmardi, Homa and Dutta, Upasana and Watts, Duncan J},journal={preprint arXiv:2606.02883},year={2026},project={/projects/LLMRec/}}